Argus: Automated Discovery of Test Oracles for Database Management Systems Using LLMs
TL;DR
Database Management Systems (DBMSs) are notoriously hard to test because you need a test oracle — a way to know if the output is correct. Prior work builds these oracles by hand, creating a never-ending cycle of manual effort.
Argus breaks this cycle by using LLMs to automatically discover test oracles, then formally verifies them with a SQL equivalence prover for soundness, and efficiently instantiates them into thousands of concrete test cases. Evaluated on five heavily-tested DBMSs, Argus found 41 previously unknown bugs (36 logic bugs), outperforming state-of-the-art manual oracle designs.
In practice, spending just ~$10 on LLM calls generates millions of reliable SQL tests — each capable of catching logic bugs, where a query silently returns wrong results instead of throwing an error.
The Problem: Test Oracles Are a Bottleneck
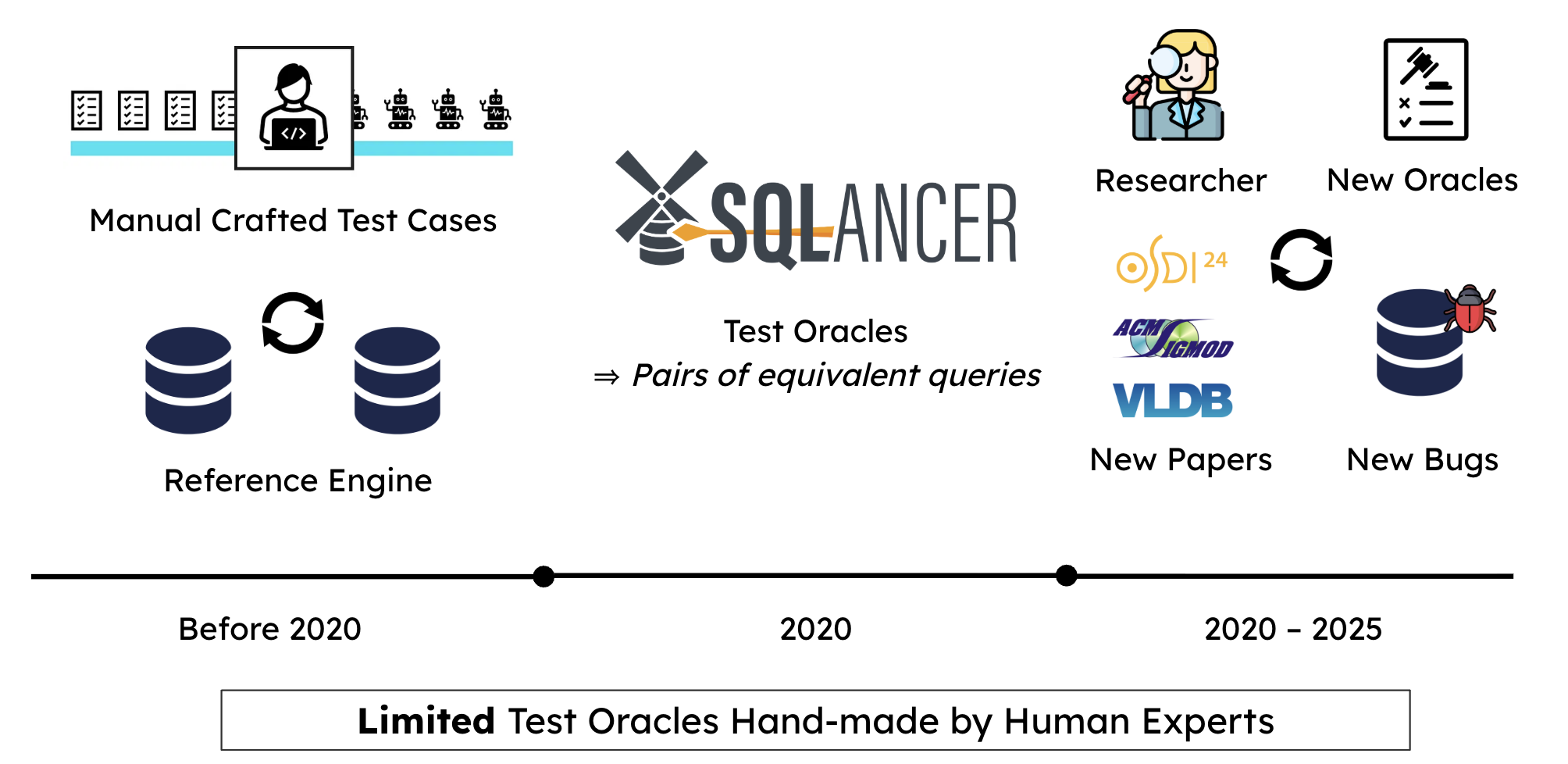
When testing a DBMS, how do you know if the result of a SQL query is correct? This is the test oracle problem. A naive approach would be to compare two DBMSs against each other, but that misses bugs they share. The dominant approach instead builds semantic equivalence oracles: transform a query \(Q\) into a semantically equivalent \(Q'\), run both, and flag inconsistencies as bugs.
The catch: designing such transformation mechanisms is entirely manual. Researchers have published over 20 top-conference papers, each hand-crafting specialized oracles — TLP, NoREC, EET, DQP — yet bugs keep slipping through. Consider this real TiDB bug that went undetected for years:
CREATE TABLE t1(c INT);
INSERT INTO t1 VALUES (1);
-- Q: Empty table filter → should return {}
SELECT c / 3 FROM t1 WHERE false; -- {} ✓
-- Oracle: Q EXCEPT Q should always be empty
SELECT c / 3 FROM t1 EXCEPT SELECT c / 3 FROM t1; -- {0.3333} ✗ (BUG!)
Catching this required the very specific insight that \(Q \setminus Q = \emptyset\). A human had to think of it. Can we make a machine do that automatically?
Key Insight: Constrained Abstract Queries (CAQ)
The core innovation in Argus is a new representation called a Constrained Abstract Query (CAQ) — a SQL query template with typed placeholders that can be filled with concrete SQL snippets.
A placeholder \(\square_i\) can be either:
-
Expr(TableName : SQLDatatype)— any expression over a table that returns a given type (e.g., a Boolean expression overt1) -
Table(SQLTableDef)— any table or subquery with a given schema
An equivalent CAQ pair \((s, q_1, q_2)\) is two CAQs that produce the same results for every possible instantiation of their placeholders. For example, the classic TLP oracle can be expressed as a CAQ pair:
-- Q₁: seed query
SELECT * FROM t1, □₁⊲Table(...);
-- Q₂: TLP three-way partition
SELECT * FROM t1, □₁⊲Table(...) WHERE (□₂⊲Expr(t1:BOOLEAN) IS TRUE)
UNION ALL
SELECT * FROM t1, □₁⊲Table(...) WHERE (□₂⊲Expr(t1:BOOLEAN) IS FALSE)
UNION ALL
SELECT * FROM t1, □₁⊲Table(...) WHERE (□₂⊲Expr(t1:BOOLEAN) IS NULL);
-- Instantiation examples:
-- □₁ ↦ t1 ASOF JOIN t2
-- □₂ ↦ json_valid(t1.c0)
The power of CAQs: one CAQ pair is a reusable oracle that can generate thousands of concrete test cases by filling its placeholders with diverse SQL snippets.
The Argus Pipeline
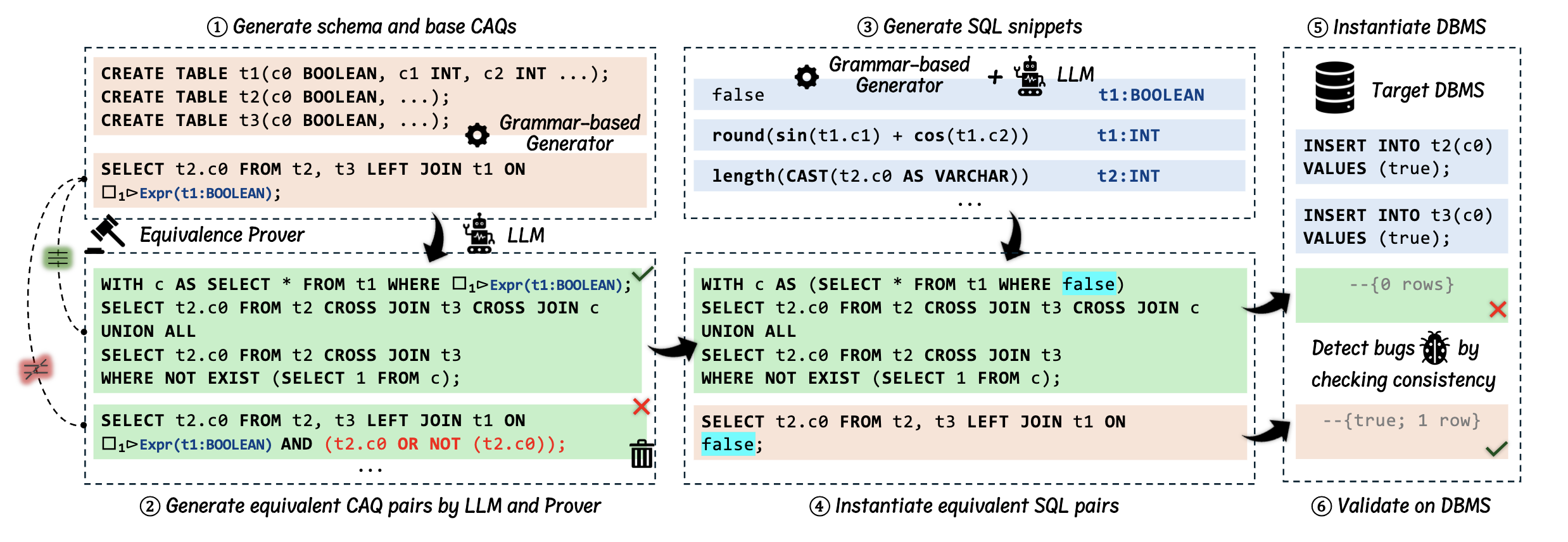
Argus operates in two stages:
Stage 1 — Test Oracle Discovery (offline, one-time)
① Database Seeding. A grammar-based generator (SQLancer) produces random database schemas and seed CAQs. Virtual columns and tables serve as placeholders, making the output compatible with SQL provers that expect concrete syntax.
② LLM-based Oracle Generation + Formal Verification. For each seed CAQ \(q\), Argus iteratively prompts an LLM to generate an equivalent variant \(q'\). Two mechanisms ensure quality:
- In-context learning — the LLM is shown verified successes (Equal set) and failures (Fail set) from previous rounds.
- Diversity-oriented sampling — verified CAQs are clustered by query-plan tree-edit distance (k-means), and samples are drawn from each cluster to push the LLM toward novel execution plans.
Every candidate \(q'\) must pass a SQL equivalence prover (SQLSolver) before acceptance. Placeholders are replaced by virtual entities so the prover can reason on concrete queries. Only formally verified pairs become test oracles — zero false positives by design.
Stage 2 — Test Case Instantiation (online, per DBMS)
③ Corpus Synthesis. A hybrid approach (LLM + grammar-based generator) pre-generates a large library of SQL snippets:
- LLMs produce complex, feature-rich expressions and table structures, guided by official DBMS documentation.
- The grammar-based generator covers corner values and edge cases systematically.
- Cross-combination: expressions are recursively composed (e.g., substituting a
Booleanexpr into anINTfunction that expects a Boolean column) to create intricate multi-level expressions. - Every snippet is runtime-validated on the target DBMS to filter type mismatches and invalid SQL.
④⑤⑥ Instantiation & Bug Detection. Each verified CAQ pair is instantiated up to \(K\) times by randomly sampling compatible snippets from the corpus. Placeholders are replaced consistently in both \(q\) and \(q'\). Random database instances are created, and the two queries are executed. Any result mismatch is a bug report.
Three general constraints on snippets guarantee that instantiated pairs remain equivalent even when concrete expressions are plugged in:
- Determinism — no
RANDOM(),CURRENT_TIMESTAMP, etc. - Null-preserving — expression returns
NULLwhen evaluated on all-NULLrows. - Empty-result-preserving — expression returns empty on an empty table.
Representative Bugs Found
📌 PostgreSQL: Incorrect json function in RIGHT JOIN
CREATE TABLE t(c INT);
INSERT INTO t VALUES (1);
-- Q1: RIGHT JOIN with FALSE → left side always NULL
SELECT sub.c FROM (
SELECT json_array_length(json_array(3, 2, t.c)) AS c FROM t
) AS sub RIGHT JOIN t ON FALSE; -- Expected: {NULL}, Got: {2} ✗
-- Q2: explicitly NULL in subquery
SELECT sub.c FROM (SELECT NULL AS c FROM t) AS sub
RIGHT JOIN t ON FALSE; -- {NULL} ✓
Root cause: PostgreSQL’s json functions bypass the null-propagation rule for RIGHT JOIN, producing incorrect non-null values. Reported and fixed within 24 hours.
📌 Dolt: EXISTS duplicates rows
CREATE TABLE t(c0 INT, c1 INT, PRIMARY KEY (c0, c1));
INSERT INTO t VALUES (1,1), (2,2), (2,3);
-- With NOT NULL primary key, EXISTS is always TRUE → should return all rows once
SELECT * FROM t WHERE EXISTS (SELECT 1 FROM t AS x WHERE x.c0 = t.c0);
-- Got: {(1,1),(2,2),(2,3),(1,1),(2,2),(2,3)} ✗ — every row duplicated!
SELECT * FROM t; -- {(1,1),(2,2),(2,3)} ✓
📌 DuckDB: Empty CTE incorrectly short-circuits UNION ALL
CREATE TABLE t1(c0 BOOLEAN);
CREATE TABLE t2(c0 BOOLEAN);
CREATE TABLE t3(c0 BOOLEAN);
INSERT INTO t2 VALUES (true);
INSERT INTO t3 VALUES (true);
-- Q1
SELECT t2.c0 FROM t2, t3 LEFT JOIN t1 ON false; -- {true} ✓
-- Q2 (equivalent via CTE expansion)
WITH c AS (SELECT * FROM t1 WHERE false)
SELECT t2.c0 FROM t2 CROSS JOIN t3 CROSS JOIN c
UNION ALL
SELECT t2.c0 FROM t2 CROSS JOIN t3 WHERE NOT EXISTS (SELECT 1 FROM c);
-- Got: {0 rows} ✗
Root cause: DuckDB incorrectly assumes an empty materialized CTE always causes the outer query to return no rows — not true with UNION ALL.
🎉 Real-world impact: Dolt officially wrote about Argus on their blog, detailing how our AI-generated SQL tests found 19 bugs in their database engine and how they are integrating the Argus-generated test suite into their regression testing process.
Evaluation Results
Bugs Found (5 DBMSs, 2-month campaign)
| DBMS | Reported | Fixed | Confirmed | Logic Bugs |
|---|---|---|---|---|
| Dolt | 19 | 18 | 19 | 18 |
| DuckDB | 8 | 6 | 7 | 4 |
| MySQL | 8 | 0 | 5 | 8 |
| PostgreSQL | 1 | 1 | 1 | 1 |
| TiDB | 5 | 2 | 5 | 5 |
| Total | 41 | 27 | 36 | 36 |
36 out of 41 bugs are logic bugs — the silent, most dangerous class that cause incorrect query results without any error. Compared to recent works with manually crafted oracles, Argus finds more despite targeting DBMSs already extensively tested.
Code Coverage
On DuckDB (24-hour run):
- Argus achieves +19.9% line coverage and +18.1% branch coverage over
SQLancer++ - 5.5× line and 6.4× function metamorphic coverage over
SQLancer— metamorphic coverage measures how much code is exercised differently between the two equivalent queries, directly correlating with logic bug-finding ability
On PostgreSQL:
- Outperforms
SQLancer++by +19.0% line and +22.5% branch coverage - Covers 23 query features (vs
SQLancer’s 15 inpglast), demonstrating the LLM’s ability to generate feature-rich queries
New Oracles vs. Prior Manual Oracles
In a head-to-head comparison on Dolt v1.0.0 (6-hour window), using the same snippet corpus and CAQ format for fairness:
- Argus-5,000 oracles: found 10 unique logic bugs
- Baseline (union of
TLP+NoREC+EET+DQP— 11 hand-crafted oracles): found 3 - Argus-50 oracles (fewer than baseline): found only 2, confirming the quantity of oracles matters
The 3.33× improvement demonstrates that automation unlocks oracle diversity that manual design simply cannot match at scale.
Cost & Efficiency
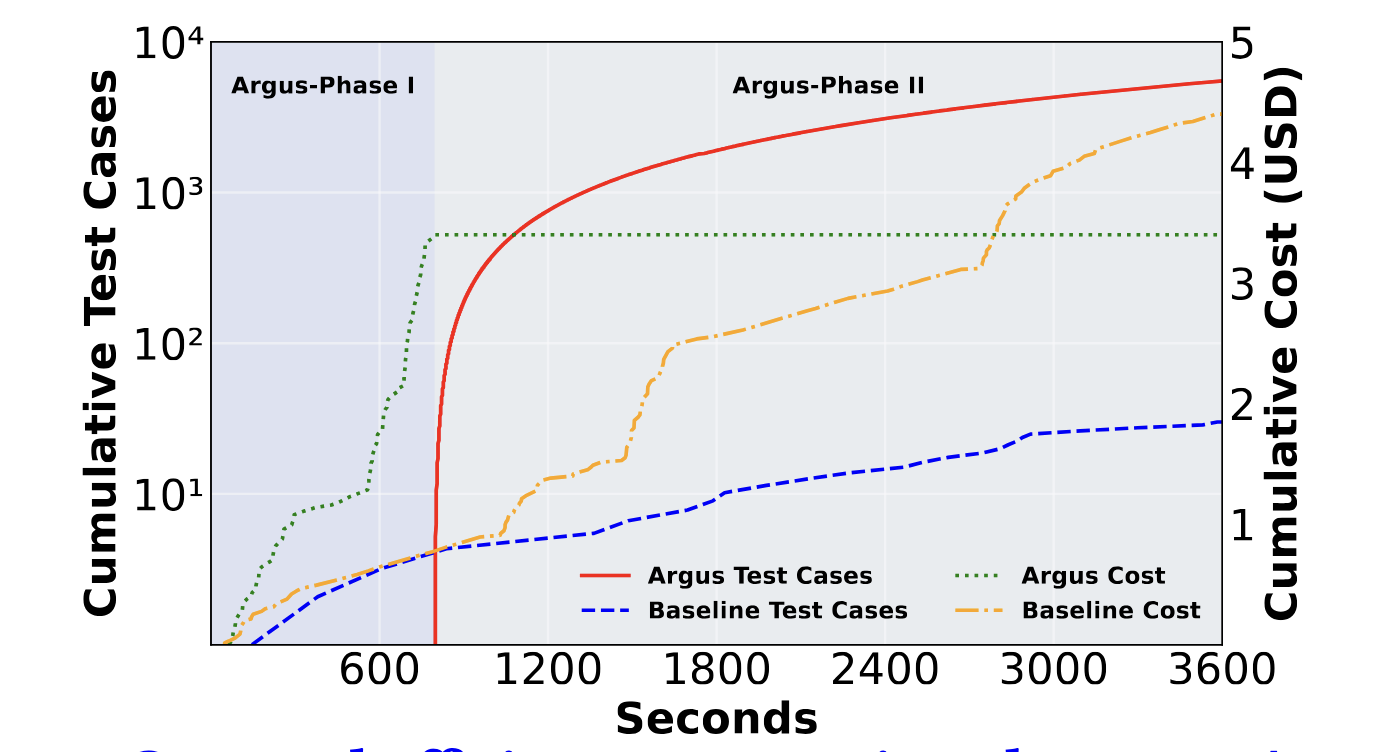
Argus’s two-stage design is dramatically more efficient than a naive LLM baseline that generates full concrete query pairs directly:
| Cost Item | Phase | Cost |
|---|---|---|
| CAQ pair generation | Offline · one-time | ~$3 |
| Snippet corpus (100,000 snippets) | Offline · per DBMS | ~$12 |
| Instantiation & test execution | Online · reusable | FREE |
The naive baseline generates test cases orders of magnitude more slowly because it must call the LLM for every single test case.
Soundness: Why the SQL Prover Matters
When we replaced the SQL equivalence prover with LLM-as-a-judge (using GPT-5):
- 20 consecutive bug reports were all false positives
- Among 20 LLM-judged-equivalent CAQ pairs, 1 was actually inequivalent (5% error rate)
In mature DBMSs, finding a single real bug may require thousands of queries. Even a 5% error rate overwhelmingly drowns out true bugs. The prover is not optional — it’s what makes Argus practical.
What Makes Argus Different
| Aspect | Prior work | Argus |
|---|---|---|
| Oracle design | Manual, expert-crafted | Automated by LLM |
| Soundness | Assumed correct | Formally verified by SQL prover |
| Scalability | ~10s of hand-written oracles | Thousands of verified CAQ pairs |
Discussion
Prover limitations are opportunities. SQL equivalence provers currently support a subset of SQL features (core Calcite syntax: outer joins, nested queries, basic aggregations). Argus’s two-stage design mitigates this by proving equivalence at the abstract CAQ level, then instantiating placeholders with complex, DBMS-specific snippets that go beyond the prover’s reasoning capabilities.
We also found prover bugs. During development, Argus revealed 10 bugs in SQLSolver and QED — incorrect equivalence proofs that would have caused false positives. All were fixed quickly. Improving Argus simultaneously improves the tools it depends on.
Extensible by design. Argus can be steered toward specific SQL features simply by adjusting the LLM prompt (e.g., “ensure the generated snippet includes at least one OUTER JOIN”). No code changes needed.
Future directions. Two natural extensions:
- Expand the target domain. Argus’s core idea — using LLMs to discover semantic equivalences and formally verifying them — is not specific to relational DBMSs. The same paradigm could apply to compilers (e.g., finding equivalent IR transformations that expose miscompilation bugs), network systems (e.g., equivalent packet-forwarding rules that reveal routing inconsistencies), or graph/spatial databases (e.g., equivalent graph traversal queries). Any domain with a formal notion of equivalence and a verifier is a candidate.
- Oracle prioritization. Given thousands of LLM-generated oracles, which are most likely to find bugs in a specific DBMS? Combining coverage feedback, historical bug patterns, and oracle structural diversity could guide Argus toward higher-yield test oracles.
Citation
@misc{mang2025argus,
title = {Automated Discovery of Test Oracles for Database Management Systems Using LLMs},
author = {Qiuyang Mang and Runyuan He and Suyang Zhong and Xiaoxuan Liu and Huanchen Zhang and Alvin Cheung},
year = {2025},
eprint = {2510.06663},
archivePrefix = {arXiv},
primaryClass = {cs.DB},
url = {https://arxiv.org/abs/2510.06663}
}
This work was accepted at SIGMOD 2026. Find out more: [arXiv] [Slides] [Dolt Blog]