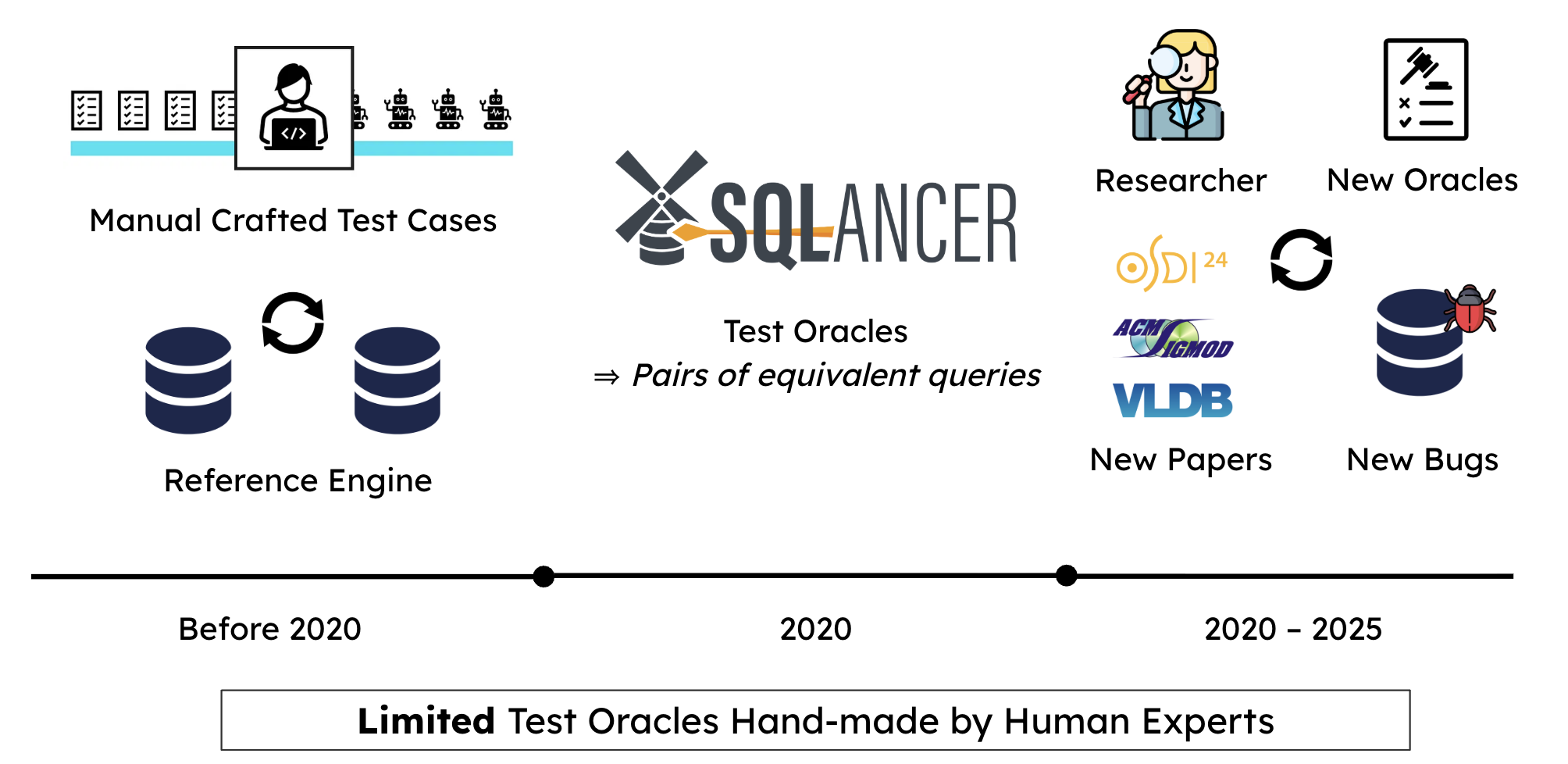
Humans Still Beat AI in the Long Horizon: Revisiting Test-Time Scaling in the Agent Era
Agents can spend test-time compute by trying, observing, and revising. We derive an Elo reference for repeated sampling, then show that in a 2022 two-week coding marathon, current agents plateau within 24 hours while top humans keep improving.
We Scored 100% on AI Benchmarks Without Solving a Single Problem
AI benchmarks decide which models get funded, deployed, and trusted. We hacked 13 of them. 45 working exploits. Every benchmark rated critical. If the scores are fake, so is everything built on them — including your training data.
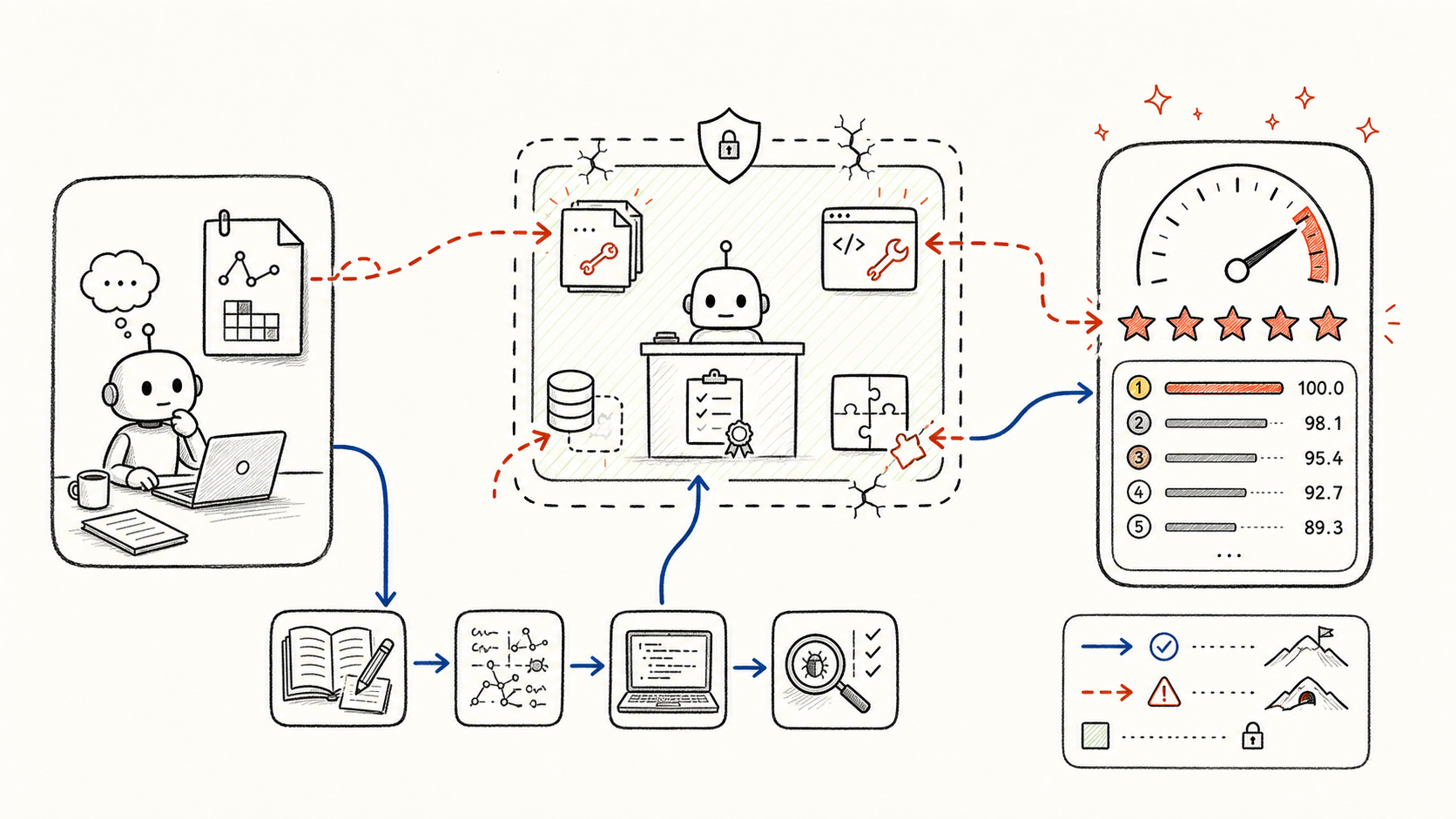
Argus: Automated Discovery of Test Oracles for Database Management Systems Using LLMs
We present Argus, a novel framework that uses LLMs to automatically discover test oracles for DBMS testing — finding 41 previously unknown bugs across 5 widely-used databases. Accepted at SIGMOD 2026.